React Queryを状態管理ライブラリとして使い倒そう!/useQStateのススメ
ことしもQiitaでアドベントカレンダーを書きました。 こちらにもリファレンスを貼っておきます。
ReactでAirtableのAPPS(アプリ)を作ろう!!
最近はNoCodeツールに興味をもっています。今年のアドベントカレンダーでは、以下の記事「ReactでAirtableのAPPS(アプリ)を作ろう!!」を書きました。
React-SpringのHooksベースAPIでブラウザアニメーションを基本から極めよう!
React-SpringのHooksベースAPIでブラウザアニメーションを基本から極めよう!という記事をQiitaに書きました。

React-SpringというモダンなReact用のアニメーショライブラリ2を見つけて、Reactであれば! Hooksであれば!理解できそうなので(理解したとは言っていない)、解説記事を書いてみました。
- はじめに
- 対象読者
- この文章の位置付け
- アニメーションとは何か
*「連続的に変化する」とはどういうことか
- 連続的変化を表現するための方法
- react-springの紹介
- やってみようReact-Spring
- API説明
- おわりに
- 参考リンク
Reactベース静的サイトジェネレータGatsbyの真の力をお見せします
Reactベース静的サイトジェネレータGatsbyの真の力をお見せしますという記事をQiitaに書きました。
「「爆速サイト」が必要ない場合でも得られるGatsbyの利点」などを書いています。 GraphQLは良いものだ。
Grails&React CRUDビュー生成2017 〜Reactベースの管理画面構築ライブラリAdmin-On-Restの紹介〜
これはG*Advent callender 2017の24日の記事です。 昨日23日の記事は mshimomuさん、明日25日の記事は未定です。
完全に一年ぶりの記事です。みなさん、いかがお過しでしたでしょうか。今年Qiitaとかに書いた記事を別にまとめましたが、わたしはReactを良く書いてた一年でした。
本記事のテーマは以下の2つです。
- GrailsのWeb APIサーバのCRUDビューをいかに簡単に作るか
- RESTfulサーバ/任意のサーバに対する強力なダッシュボード・管理コンソール開発用ReactコンポーネントライブラリであるAdmin-On-Restの紹介、使い方
もくじ
- もくじ
- 去年までのあらすじと今年の方針
- Admin-On-Restとは何か
- Admin-On-Restのデモ動画
- Admin-On-Restの特記すべき点
- REST Clientによるデータソースの抽象化
- Admin-On-RestをGrailsに繋ごう
- Admin-On-Restのカスタマイズ
- デモ
- まとめ
- GraphQLはどこへ行ったの
- ポエム
去年までのあらすじと今年の方針
一昨年のG*Advent Calendarと昨年のG*Advent Calendarでは、バックエンドを「GrailsのRESTfulなWeb APIサーバ」それをCRUDするWebアプリケーションフロントエンドを「React SPA(redux,react-router,..)」という組合せで開発し、ボイラープレート(雛形)として実装しました。
さらに去年は、GrailsのドメインクラスからJSON Schemaを自動生成し、テーブルや入力フォームを生成するという工夫をしたのでした。 さて、今年はAdmin-On-RestというReactベースの素敵なライブラリがありますのでこれを使ってみます。
Admin-On-Restとは何か
Admin-On-Restは、主にRESTfulサーバをバックエンド(データ供給源)として、そのデータをテーブル形式のCRUD編集や ページネーション表示するようなWebアプリケーションを構築するためのライブラリです。用途としては管理画面を作ることを想定しているようです。RailsでいうRailsAdminみたいなものですね。
Admin-On-Restはreact-router, redux, redux-form, redux-saga, material-ui, i18n,認証などのReactでの定番の機構を用いて疎結合かつ汎用的に作られており、管理画面の構築のみならず、アプリの基本構造として使用できますし、他のアプリに部品として組込むこともできます。 過去にAngularJS用の高機能な管理画面ライブラリとして有名だったng-adminの開発チームがReactに移行して作っているようです。
Admin-On-Restのデモ動画
github.com
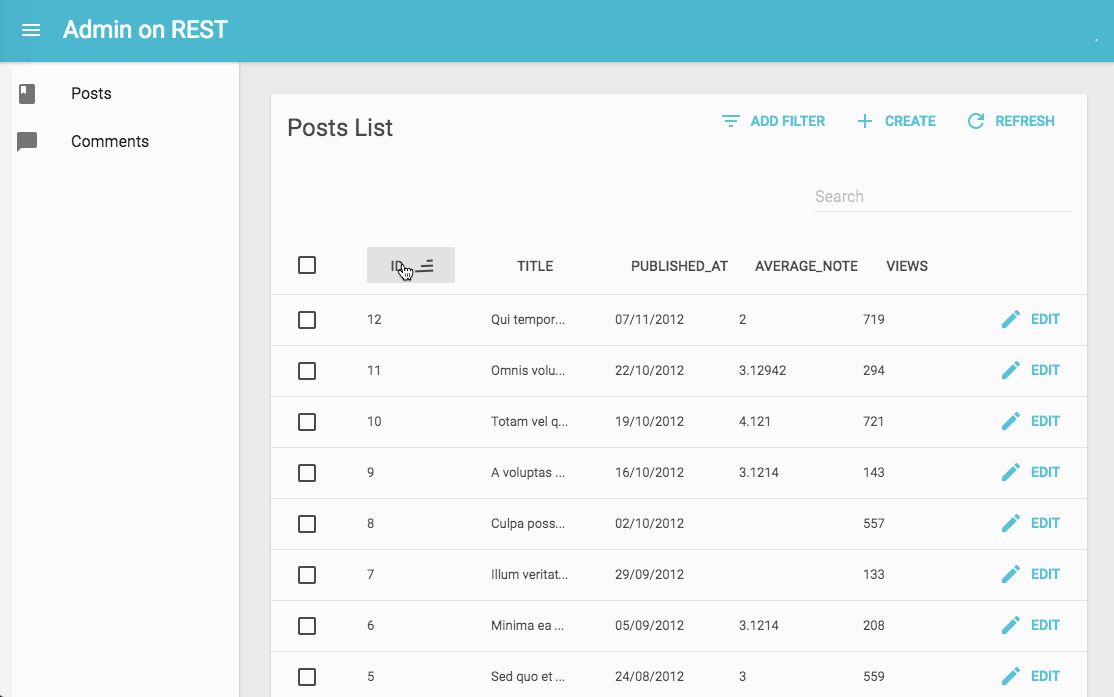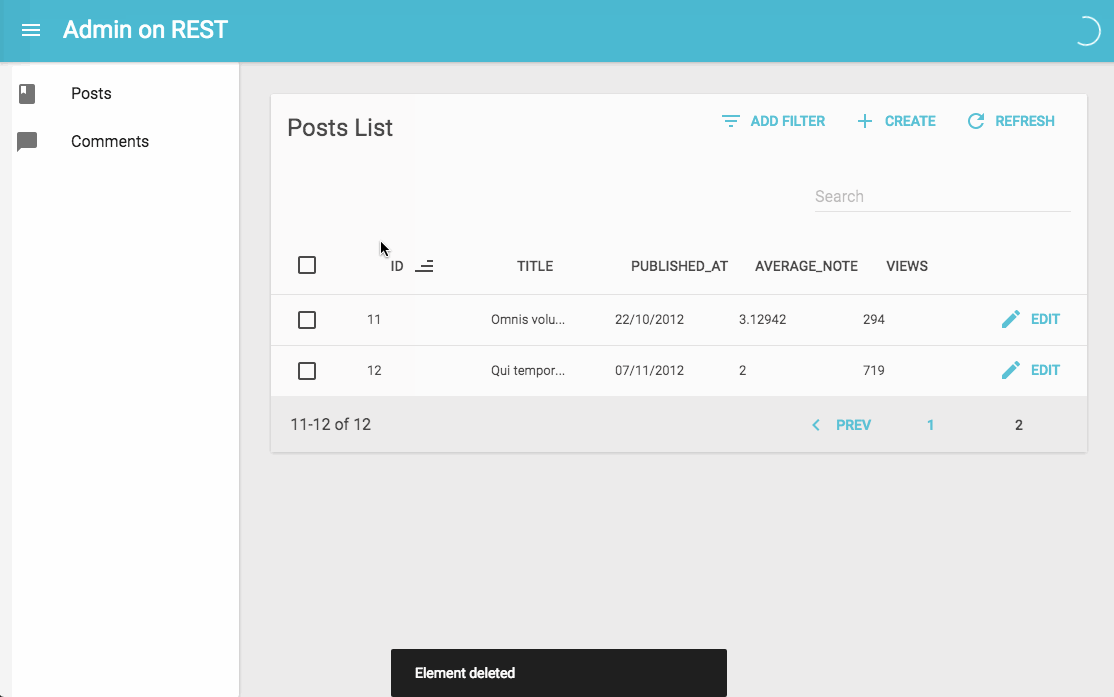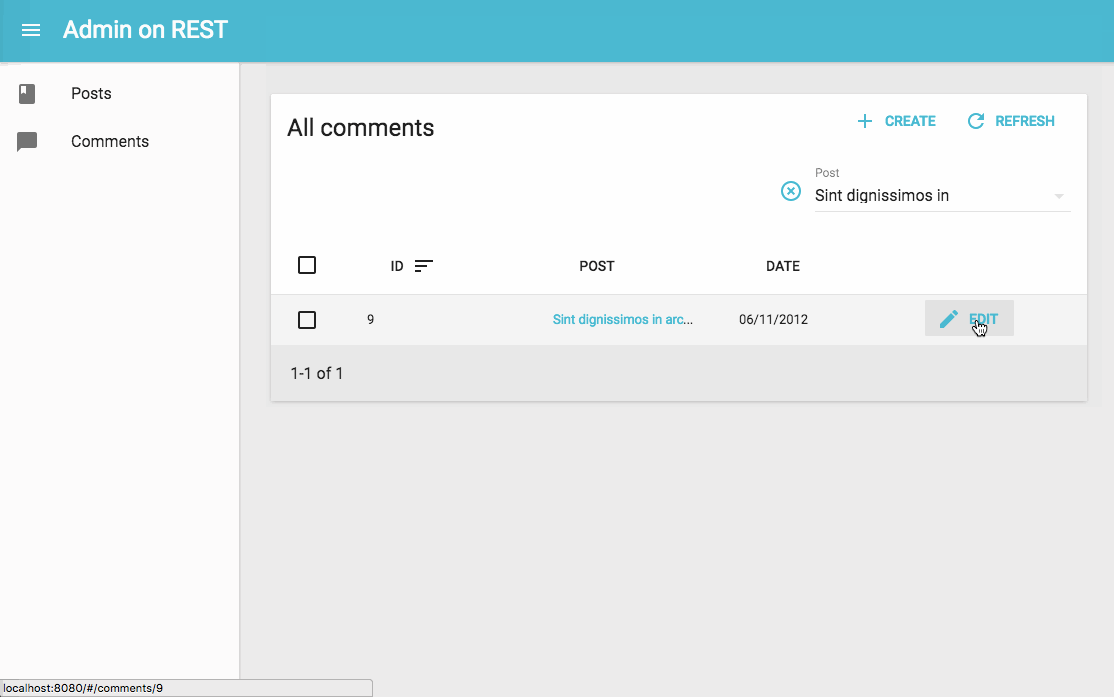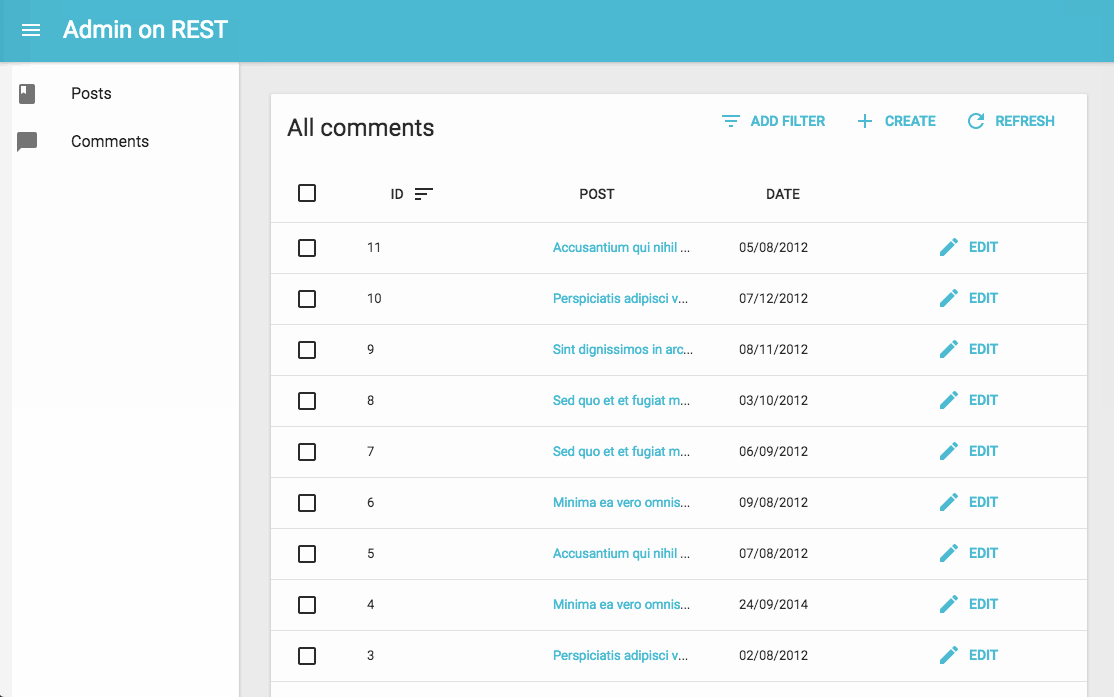 (https://marmelab.com/admin-on-rest/Tutorial.html より引用)
(https://marmelab.com/admin-on-rest/Tutorial.html より引用)
admin-on-rest demo from Francois Zaninotto on Vimeo.
Admin-On-Restの特記すべき点
Admin-On-Restの特徴は、高機能さと、カスタマイズ性の両立です。react-router, redux, redux-form, redux-sagaなどを活用することによって、Reactというコンポーネント指向ライブラリの利点を如何なく発揮しています。「簡単に使いたければ簡単に」「実務的に必要があれば徹底的にカスタマイズする」ことができ、かつ保守性可読性を規模にスケールさせて維持し続けることができます。これはページ遷移ベースのサーバサイド画面生成技術では、人間の知力を前提にすると現実的には不可能だったことです。Reactが切り開く地平(の序の口)とも見ることができるでしょう。
REST Clientによるデータソースの抽象化
Admin-On-RestはもちろんGrailsに依存するものではありません。バックエンドは任意のRESTful Web APIサーバにも留まらず、 「データを供給する何か」として抽象化されて扱われます。以下はadmin-on-restのページにある説明図ですが、
 (https://github.com/marmelab/admin-on-rest/blob/master/docs/index.md より引用)
(https://github.com/marmelab/admin-on-rest/blob/master/docs/index.md より引用)
上でいう「REST Client」は実はデータ集合を扱う基本操作を備えた汎用的なデータプロバイダー/コネクタであり、 コネクタには標準で添付されるもの以外に以下があります。
- Epilogue: dunghuynh/aor-epilogue-client
- Feathersjs: josx/aor-feathers-client
- Firebase: sidferreira/aor-firebase-client
- Parse Server: leperone/aor-parseserver-client
- LoopBack: kimkha/aor-loopback
- JSON API: moonlight-labs/aor-jsonapi-client
- GraphQL: marmelab/aor-simple-graphql-client (uses Apollo)
- Local JSON: marmelab/aor-json-rest-client. It doesn't even use HTTP. Use it for testing purposes.
- RDBMS
GraphQLは後述します。その他のフレームワークやサービス(やRDBMS)に対するものは、いずれも大きく言えばRESTfulなWebAPIに対するものなわけで、 なぜそれぞれにバリエーションが必要かといえば、特にページネーションを実現するための部分取得や、データ集合全体でどのページ範囲を見ているかを表現する流儀が異なるからです。
Admin-On-RestをGrailsに繋ごう
Grailsに繋ぐためには、GrailsのRest API自動生成で作られるAPIに対応したコネクタ(REST Client)を探すか設定するか作るか、あるいはGrails側で生成されるAPIの実装コードをカスタマイズして、上のいずれかと互換のある動作をするように変更する必要があります。今回は、Grails用のコネクタを作成します。
ちゃっちゃっと行きます。成果物のソースはこちら。
プロジェクト作成
Grailsのreactプロファイルを使用してプロジェクトを初期作成します。
# sdk use grails # SDKMAN使用 Using grails version 3.3.2 in this shell. # grails create-app --profile react grailsReactAdminOnRest # cd grailsReactAdminOnRest
reactプロファイルはGradleのマルチプロジェクト構成になっており、serverディレクトリ配下にgrailsアプリが、clientディレクトリ配下にcreate-react-appを使用したReactアプリが作成されます。
% tree -L 2 . ├── README.md ├── client │ ├── README.md │ ├── build.gradle │ ├── node_modules │ ├── package-lock.json │ ├── package.json │ ├── public │ ├── src │ └── yarn.lock ├── gradle │ └── wrapper ├── gradlew ├── gradlew.bat ├── server │ ├── build │ ├── build.gradle │ ├── gradle.properties │ ├── grails-app │ ├── grails-wrapper.jar │ ├── grailsw │ └── grailsw.bat └── settings.gradle
ドメインクラス作成
BookとAuthorの2つのドメインクラスを作成します。BookはAuthorに所属するn:1の関連を持たせます。
// server/grails-app/domain/sample/Book.groovy package sample import grails.rest.* @Resource(uri='/api/book') class Book { String title Integer price static belongsTo = [author: Author] }
// server/grails-app/domain/sample/Author.groovy package sample import grails.rest.* @Resource(uri='/api/author') class Author { String name static hasMany = [books: Book] }
APIサーバの動作確認
# grails run-app
別端末から確認
% curl -X GET http://localhost:8080/author [] % curl -X POST --header 'Content-Type: application/json' http://localhost:8080/author.json -d '{"name":"uehaj"}' {"id":1,"name":"uehaj"} % curl -X POST --header 'Content-Type: application/json' http://localhost:8080/author.json -d '{"name":"yamada tarou"}' {"id":2,"name":"yamada tarou"} % curl -X GET http://localhost:8080/author [{"id":1,"books":[],"name":"uehaj"},{"id":2,"books":[],"name":"yamada tarou"}] % curl -X POST --header 'Content-Type: application/json' http://localhost:8080/book -d '{"title":"Groovy Programming", "price":1800}' {"message":"[class sample.Book]クラスのプロパティ[author]にnullは許可されません。","path":"/book/index","_links":{"self":{"href":"http://localhost:8080/book/index"}}} % curl -X POST --header 'Content-Type: application/json' http://localhost:8080/book -d '{"title":"Groovy Programming", "price":1800, "author": 1}' {"id":1,"title":"Groovy Programming","price":1800,"author":{"id":1}} % curl -X GET http://localhost:8080/book/1 {"id":1,"title":"Groovy Programming","price":1800,"author":{"id":1}}
サーバ側の端末に戻ってGrails APIサーバをいったん落しておきます。
^C
以降は、すべてクライアント側の設定やコード追加になります。
クライアントの初期化
clientディレクトリ配下にはpackage.jsonを含むNPMのプロジェクトが作成されています。(create-react-appベース)
不要なNPMモジュールをuninstall、不要なソース削除します。。
# cd ../client # npm uninstall react-bootstrap # rm -r src/App* src/css src/images
admin-on-restをNPMモジュールとしてインストールします。
# npm install -S admin-on-rest
Reactアプリとしての入り口を定義
index.jsを以下のように定義します。create-react-appが生成するindex.jsから不要なCSSのimportを削除しただけです。
// client/src/index.js import React from 'react'; import ReactDOM from 'react-dom'; import App from './App'; ReactDOM.render( <App />, document.getElementById('root') );
上でimportされているApp.jsは以下のように定義します。 AdminコンポーネントはAdmin-On-Restで構成するアプリのトップレベルのコンポーネントです。
// client/src/App.js import React from 'react'; import { simpleRestClient, Admin, Resource } from 'admin-on-rest'; import * as Config from './config'; export default props => ( <Admin simpleRestClient={simpleRestClient(Config.SERVER_URL)} /> );
サーバとクライアントの両起動
これで一応クライアントも起動するはずなので、サーバとクライアントの両方起動してみます。
# cd .. # ./gradlew bootRun -parallel
ブラウザのhttp://localhost:3000/が開き以下の画面が表示されると思います。 リソースが定義されていないので表示内容は空です。

Grails用REST Client の作成
simple.jsを元にして以下の細工をします。
- ページネーションの修正
- ソート順序の指定をGrailsに合せる(sort=[field,order]→sort=, order=)
- filterの処理はとりあえず今回は無視する
作成したgrallsRestClient.jsのソースはこちらにあります。
Admin-On-Restのカスタマイズ
さて上記の準備ができたならば、あとはAdmin-On-Restで画面を作っていくという話になります。(Grailsとは独立)。 基本的に、リソースを追加していくとそれがページになります。
表示リソースの追加(Author)
まず、Authorリソースを作成編集できるように修正していきます。 Authorリソースの編集のための画面コンポーネント群を定義するsrc/resources/author.jsを以下の内容で作成します。
// client/src/resources/author.js import React from 'react'; import { List, Datagrid, Edit, Create, SimpleForm, TextField, EditButton, DisabledInput, TextInput, } from 'admin-on-rest'; import ErrorBoundary from '../ErrorBoundary'; import Pagination from '../Pagination'; import AuthorIcon from 'material-ui/svg-icons/social/person'; export { AuthorIcon }; export const AuthorList = props => ( <ErrorBoundary> <List {...props} pagination={<Pagination />}> <Datagrid> <TextField source="id" /> <TextField source="name" /> <EditButton basePath="/author" /> </Datagrid> </List> </ErrorBoundary> ); const AuthorTitle = ({ record }) => { return <span>Author {record ? `"${record.title}"` : ''}</span>; }; export const AuthorEdit = props => ( <ErrorBoundary> <Edit title={<AuthorTitle />} {...props}> <SimpleForm save={() => console.log('save')}> <DisabledInput source="id" /> <TextInput source="name" /> </SimpleForm> </Edit> </ErrorBoundary> ); export const AuthorCreate = props => ( <ErrorBoundary> <Create title="Create a Author" {...props}> <SimpleForm> <TextInput source="name" /> </SimpleForm> </Create> </ErrorBoundary> );
ここでExportしているコンポーネント群(AuthorList, AuthorEdit, AuthorCreate, AuthorIcon)を使い、App.jsのAdminコンポーネントの子要素としてResourceコンポーネントを配置します。
// client/src/App.js import React from 'react'; import { simpleRestClient, Admin, Resource } from 'admin-on-rest'; import { AuthorList, AuthorEdit, AuthorCreate, AuthorIcon, } from './resources/authors'; import * as Config from './config'; export default props => ( <Admin simpleRestClient={simpleRestClient(Config.SERVER_URL)} > <Resource name="author" list={AuthorList} edit={AuthorEdit} create={AuthorCreate} icon={AuthorIcon} /> </Admin> );
これでクライアントで以下のようにAuthorを追加、編集できるようになります。 AuthorからBookへの依存がないので、Bookを作成しなくても作成できます。


表示リソースの追加(Book)
次に、Bookリソースの編集機能を追加します。 画面コンポーネント群を定義するsrc/resources/book.jsを以下の内容で作成します。
Bookは外部キーでAuthorを参照しているので、画面上での参照・編集できるように
// cliet/src/resources/book.js import React from 'react'; import { List, Datagrid, Edit, Create, SimpleForm, TextField, EditButton, DisabledInput, TextInput, NumberInput, ReferenceInput, ReferenceField, SelectInput, } from 'admin-on-rest'; import ErrorBoundary from '../ErrorBoundary'; import Pagination from '../Pagination'; import BookIcon from 'material-ui/svg-icons/action/book'; export { BookIcon }; export const BookList = props => ( <ErrorBoundary> <List {...props} pagination={<Pagination />}> <Datagrid> <TextField source="id" /> <TextField source="title" /> <TextField source="price" /> <ReferenceField label="Author" source="author.id" reference="author"> <TextField source="name" /> </ReferenceField> <EditButton basePath="/book" /> </Datagrid> </List> </ErrorBoundary> ); const BookTitle = ({ record }) => { return <span>Book {record ? `"${record.title}"` : ''}</span>; }; export const BookEdit = props => ( <ErrorBoundary> <Edit title={<BookTitle />} {...props}> <SimpleForm> <DisabledInput source="id" /> <TextInput source="title" /> <NumberInput source="price" /> <ReferenceInput label="Author" source="author.id" reference="author"> <SelectInput optionText="name" /> </ReferenceInput> </SimpleForm> </Edit> </ErrorBoundary> ); export const BookCreate = props => ( <ErrorBoundary> <Create title="Create a Book" {...props}> <SimpleForm> <TextInput source="title" /> <NumberInput source="price" /> <ReferenceInput label="Author" source="author.id" reference="author" allowEmpty> <SelectInput optionText="name" /> </ReferenceInput> </SimpleForm> </Create> </ErrorBoundary> );
外部キー参照するフィールドについて、BookListではReferenceFieldを、BookEdit, BookCreateではReferenceInputを使用します。BookCreateではReferenceInputコンポーネントにallowEmpty属性を指定する必要があります。
Grailsが出力するBookのJSONレコードには、authorに対する外部キーが、
{"id":1,"title":"Groovy Programming","price":1800,"author":{"id":2}}
のように含まれるため、ReferenceField、ReferenceInputのsource属性に"author.id"を指定しています。
Bookリソースを増やしたのでApp.jsのAdmin配下にResourceコンポーネントを追加します。
// client/src/App.js : export default props => ( <Admin restClient={restClient(Config.SERVER_URL)}> <Resource name="book" list={BookList} edit={BookEdit} create={BookCreate} icon={BookIcon} /> <Resource name="author" list={AuthorList} edit={AuthorEdit} create={AuthorCreate} icon={AuthorIcon} /> </Admin> );
これによって生成される新規作成や編集画面は以下のようになります。BookのauthorフィールドはAuthorへの外部キーなので、AuthorレコードのnameからAPIを通じて引っぱってきて選択肢として表示されています。

その他
React 16を使用するので、異常時の結果を判りやすくするためのコンポーネントErrorBoundary.jsをこちらを参考にして使用します。
また、デフォルトのAdmin-on-Restのページネーションでは全ページへのリンクを表示できるがその機能を除去したバージョンのページネーションUI Pagination.jsを作成します。
デモ
オンラインデモ準備は間に合いませんでした。できたらリンクはります。 ソースコードはこちらにあります。
まとめ
以上のように、ページベースアプリではなく、Web API化することで、クライアントはGrailsとは完全に独立したものを使用できるようになるわけです。Admin-On-Restは発展甚しく、機能も汎用性も高いので、是非使っていきたいところです。
もっとも、去年はJSON Schemaでドメインクラスからメタ情報を抽出し、表の項目やフォーム画面なのカスタマイズ、バリデーション処理なども生成することを試みました。今年はそこが抜けていて、フィールドの順序やフォーム中のデータ項目を明示的に指定していく必要はあります。
GraphQLはどこへ行ったの
GraphQLはRESTfulのカウンターとして出てきた技術で、高機能高効率なクエリを可能にすると同時にAPIを強く型付けするものです。
GrailsにはGORM GraphQLプラグインがあり、ドメインクラスを元にして、QraphQLスキーマの生成や、grapql browserの組込み、さらにはGraphQLクエリに対するハンドラの実装を行うことができ、一般的なサーバサイドのGraphQLソリューションが実現されています。
さらに、前述のようにAdmin-On-Restはapollo-clientをベースとしたGraphQLコネクタ(aka RestClient)を利用可能です。
ですので、当初のアドカレの予告タイトルではGraphQLでやったるで! というのを狙っていたのですが、調べていく内に(時間がなくなった!というのもありますが)、今いまでは、管理画面程度のデータの列挙や編集のために、GraphQLを適用するのはかならずしもベストではないな、と思っています。
その理由は、なんだかんだいってRESTful APIは、ページネーションとかは微妙に違がっていても、さまざまなサーバをまたがって共通的なモデルではあるわけです。カスタマイズもたかがしれてます。
GraphQLは、高機能でありもちろんページネーション的なものを実現可能ですが、いくつかの流儀があって、つまりRelayなのかGraphcoolなのか独自なのか、といった屋上屋的な規約が必要です。GrailsのGORM GraphQLプラグインは素のGraphQLしかないので、たとえばGraphchool規約に従うようなGraphQLマッピングを追加する、もしくは逆にGraphQLコネクタをaor-simple-graphql-clientなどを元にして修正していく必要があります。(ここらへん、GraphQLに詳しくないので嘘言ってるかも! 自信なし)
でもそういう接続を自分でやったとしてもその選択がメジャーになるのかはわからないし、今後Grails側かクライアント側かで発展して、GraphQLがアウトオブボックスで簡単に繋がるプラグインかコネクタが今後できてくるんではないかと踏んでいます。
そういうわけで、現時点でGrailsで管理画面を実装する程度では、RESTfulを採用した方がリーズナブルで現実的であり、特に他の理由でGraphQLサーバを仕立てたいのでない限りは、RESTfulで良いと考えています。
なお、GORM GraphQLプラグインはまだ使い込んではいませんが、GraphQLのカスタムオペレータやフェッチャーを定義する形態として、データと表裏一体に定義できる、GrailsのGORM上のDSLというのは筋が良いと思っています。
ポエム
過去にフレームワークと呼ばれたものは、構成要素に分解され、疎結合化されていく時代です。分解された要素はマイクロサービスで実現されるかもしれないし、クラウドプロバイダーが提供する機能や、FaaSで代替されるのかもしれません。要するに、フレームワークが分解し、「クラウドプラットフォーム全体が大きなフレームワークになった」のです。
そのような現代および未来のプログラミングの主眼はAPIの接合にあり、UI部はSPAがまかないます。この記事シリーズは、そういう流れでフレームワークやクラウドを捉えています。
Reactがなぜ重要か
この観点からは、まずUI部に関して、今回のAdmin-On-Restを含むさまざまなイノベーションがReact界隈から連続的に生まれてきています。Reactは今後も圧倒的に注目すべき技術であると思います。個人的にはMaterial-UI-Next、React Nativeが注目です。
GrailsとはGORMである
そしてGrailsをこの「クラウド=分解されたフレームワーク」論から見ると、Grailsの価値はデータ表現のDSL、ORMが残ると言えます。GORMを書きやすく扱いやすくするシステムがGrailsなのです。GORM GraphQLプラグインはその応用例の一つです。
みなさま、ではメリークリスマス and 良いお年を!